Elasticseasrch简介
Elasticsearch相关
Elasticsearch和Mysql中概念对比
Relational DB -> Databases -> Tables -> Rows -> Columns
Elasticsearch -> Index -> Types -> Documents -> Fields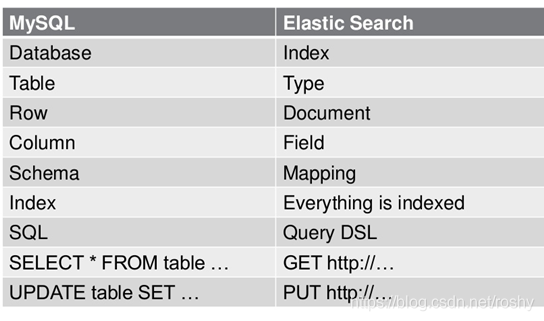
一般使用方式
- 一般通过elasticsearch集群暴露的rest接口访问,接口都符合restful风格,如获取/搜索使用http get,新增/修改使用http put等
- 索引(数据库)相关:https://www.elastic.co/guide/en/elasticsearch/reference/5.6/indices.html
- 文档(数据)相关:https://www.elastic.co/guide/en/elasticsearch/reference/5.6/docs.html
- 搜索相关:https://www.elastic.co/guide/en/elasticsearch/reference/5.6/search.html
数据类型和数据库数据结构定义
https://www.elastic.co/guide/en/elasticsearch/reference/5.6/mapping.html
- elasticsearch对于数据存储也有不同数据类型,如果未手动指定,会在第一次出现这个field的时候自动决定数据类型
常用的有: - text:用来搜索的基本类型,会根据analyzer进行分词整理,做成倒排表
- keyword:用来搜索或过滤,不会分词
- date:日期格式
- completion:对某个text类型的field的补充,用来自动补全,速度比一般搜索更快
- long, double:数值类型
- boolean:布尔类型
- ip:专门存储ip的,支持ipv4和ipv6,支持范围搜索
- object:支持嵌套封装
索引(数据库)一般配置
https://www.elastic.co/guide/en/elasticsearch/reference/5.6/indices-create-index.html
- number_of_shards:分片数,默认5,只能在创建index时确定,无法修改
- number_of_replicas:副本数,默认1,可以动态修改
Suggester
https://www.elastic.co/guide/en/elasticsearch/reference/5.6/search-suggesters.html
- elasticsearch自带的提示器,包括term、phrase、completion、context
- term suggester根据编辑距离推荐分词,主要是用来提示近似词和修复拼写错误
- phrase suggester和term suggester相似,区别是不是完全把输入内容分隔成单词term,而是根据词频等选择更好的词和词组
- completion suggester用来自动补全和search-as-you-type,使用FST结构存储,保证更高效的返回搜索结果,注意这里存储在内存空间,较为消耗资源。而且这里是以前缀匹配的
- context suggester是对completion的补充,可以对指定context的结果进行加权,例如给completion字段添加分类,搜索时对指定分类结果进行分数加权
field类型search-as-you-type
https://www.elastic.co/guide/en/elasticsearch/reference/7.6/search-as-you-type.html
- 7.0新增类型,通用实现的自动补全功能,实际实现方式是自动添加了1gram,2gram,3gram过滤器,用来提高搜索效率
- 中文介绍:https://www.jianshu.com/p/32b8f8dfa99b
index-time search as you type
https://www.elastic.co/guide/en/elasticsearch/guide/master/_index_time_search_as_you_type.html
- 通过ngram算法,对内容进行多维拆分,冗余存储大量分析数据,达到高效搜索的目的。
- 实现较为简便,通过自定义analyzer的filter,设置edge-ngram的上下限区间,对内容进行分析。
自定义analyzer
https://www.elastic.co/guide/en/elasticsearch/guide/master/custom-analyzers.html
- 自定义分析器由三部分构成:character filter, tokenizer, token filter
- character filter用来清理文本,例如去除不需要的html标签等
- tokenizer分词器用来分词,standard tokenizer是通过单次边界分词并去除标点,其他例如空格分词器、关键词分词器等
- token filter分词器过滤后的内容被称为token,需要一系列的过滤器来处理,例如lowercase转换小写,stopwords去除停止词,ngram和edge-ngram是用来做部分匹配
组合条件查询
1 | GET /test_index/_search |
reindex
https://www.elastic.co/guide/en/elasticsearch/reference/current/docs-reindex.html
es无法修改field类型,如想修改只能新建index,定义mapping,然后使用reindex把老的index中的数据导入到新的index中
批量操作bulk
https://www.elastic.co/guide/en/elasticsearch/reference/5.6/docs-bulk.html
主要用来批量操作数据,减少http请求
不过注意这里的数据量也需要控制,因为数据是加载到内存的。一般建议是3000-5000文档,大小不超过15m
Java client
Low level rest client
https://www.elastic.co/guide/en/elasticsearch/client/java-rest/5.6/java-rest-low.html
使用rest请求elasticsearch集群,封装较为底层,只提供了search等接口,内容都是需要手动字符串封装,使用不便
demo:https://www.jianshu.com/p/c1f2161a5d22
High level rest client
https://www.elastic.co/guide/en/elasticsearch/client/java-rest/5.6/java-rest-high.html
从5.0版本开始提供的高级封装接口,是在low level rest client上进行的一层封装,可以较为简单的使用Java语言来构造搜索方法等,早起版本支持功能较少
demo:https://www.jianshu.com/p/871f33c2d515
spring-data-elasticsearch
早期版本的spring-data-elasticsearch模块,只支持transport client和node client,前者是直连通信客户端,后者是作为node节点的客户端
这两种方式都不是使用elasticsearch的rest接口,而是直接与集群通信。
这种方式在后期已经被elasticsearch废弃,建议使用high level rest client来构建。
Python client
客户端版本
python的elasticsearch和主版本一致,例如使用elasticsearch5.x版本的服务器,就需要安装elasticsearch5的python包
批量操作bulk
elasticsearch自带bulk接口,用来处理批量操作,使用的时候注意使用封装好的helpers来调用
demo: https://blog.csdn.net/weixin_39198406/article/details/82983256
Chrome可视化插件
简介
Elasticsearch Head,可视化插件,主要用来查看集群分片副本状态,查看基础数据等简单功能,建议复杂功能通过接口访问
https://chrome.google.com/webstore/detail/elasticsearch-head/ffmkiejjmecolpfloofpjologoblkegm
使用方式
在框中输入es集群地址,点击连接
概览页签中,下方显示的是集群节点,和各个分片在集群节点中的状态。
数据浏览中,下方显示的是es中的一些数据,可以左侧筛选指定的index和type来看
Elasticseasrch简介

