记录下一些ftp服务器相关内容,默认使用vsftpd作为服务使用
阅读更多
本文介绍jupyter中分析基础数据常用的一些工具和指令
icecast是一个音频直播流媒体服务器,支持Ogg(Vorbis和Theora),Opus,WebM和MP3流。他可以被用来创建网络电台。
官方网站
Gitlab源码地址
Icecast本身只是个直播服务器,一般使用方式是使用推流客户端(例如IceS,liquidsoap等)推流到icecast server,然后用户从icecast收听。
Relational DB -> Databases -> Tables -> Rows -> Columns
Elasticsearch -> Index -> Types -> Documents -> Fields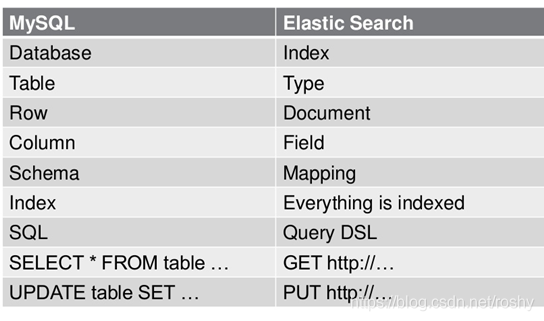
使用两个kafka connectors,一个sink connector向外部数据源(S3、ES、Hive)导出数据,一个source connector从外部源恢复数据
使用connect同步数据到s3,然后清除60天以前的数据,可以达到备份+归档且释放硬盘空间的目的
1 | grep 'crawler_news_insert' stderr.log.2020-01-29-12 | awk '{print $2}' | awk -F':' '{cnt[$2]+=1}END{for(c in cnt){print c,cnt[c]}}' | sort -n -k 1 |
1 | chage -l li |
内网环境下可以使用nc来传输文件,使用内网带宽
在机器B开启端口监听,收取文件
1 | nc -l 9999 > xxxx.zip |
机器A发送文件,指定收取端(服务器端)的ip和端口
1 | nc 192.168.1.3 9999 < xxxx.zip |
1 | # |
本文主要介绍了SpringBoot项目中如何获取真实客户端IP,在应用前侧有nginx或cdn时应该如何处理。
X-Forwarded-For(简称XFF)是一个常见的(非正式使用的)传递真实用户IP的方式,其内容一般是:
1 | X-Forwarded-For: real_client_ip, proxy1_ip, proxy2_ip |
真实用户IP会被放在第一位
总核数 = 物理CPU个数 X 每颗物理CPU的核数
总逻辑CPU数 = 物理CPU个数 X 每颗物理CPU的核数 X 超线程数
1 | # 查看物理CPU个数 |
1 | # 安装jdk |
1 | KAFKA_MANAGER_USERNAME="admin" |